Rethinking Memory Management for Multi-Tiered Systems
Exploring Efficient Page Profiling and Migration in Large Heterogeneous Memory
- July 22, 2024 by
- Dong Li
The memory hierarchy in computer systems - the arrangement of different types of memory from fastest and smallest to slowest and largest - is becoming more complex. It's adding more tiers and becoming more heterogeneous (diverse in type) to cope with performance and capacity demands from applications. Multi-tier memory systems, which started from multi-socket non-uniform memory access (NUMA) architecture (where memory access time depends on the memory location relative to the processor), are now a standard solution for building scalable and cost-effective memory systems.
Most page management systems, which handle how data is organized and moved in memory, for multi-tier heterogeneous memory (HM) consist of three components:
- A profiling mechanism: This identifies performance-critical data in applications, often by tracking page accesses. A page is a fixed-length contiguous block of virtual memory.
- A migration policy: This chooses which pages to move to top tiers.
- A migration mechanism: This moves pages across tiers, ideally with low overhead.
Research Overview
Emerging multi-tiered large memory systems call for rethinking of memory profiling and migration to address unique problems unseen in traditional single- or two-tier systems with smaller capacity. The large memory capacity brings challenges to memory profiling. The limitation in profiling quality comes from (1) the rigid control over profiling overhead and (2) the ad-hoc formation of memory regions.
In addition, rich memory heterogeneity brings challenges to page migration. Existing solutions, e.g., tiered-AutoNUMA for multi-tiered memory, are built upon an abstraction extended from traditional NUMA systems. In these systems, page migration occurs between two neighboring tiers with awareness of no more than two NUMA distances (the relative cost of accessing memory from different locations). However, such an abstraction limits multi-tiered memory systems. Migrating pages from the lowest to the top tier in tier-by-tier steps requires multiple migration decisions, which can take several seconds and fails to timely migrate pages for high performance.
Our Research Approach
We argue that the following principles must be upheld to address the above problems:
- Connecting the control of profiling overhead with the profiling mechanism to enable high-quality profiling
- Building a page migration policy specifically for multi-tiered memory to achieve high performance
- Introducing awareness of huge pages (memory pages larger than the standard size, used to improve performance)
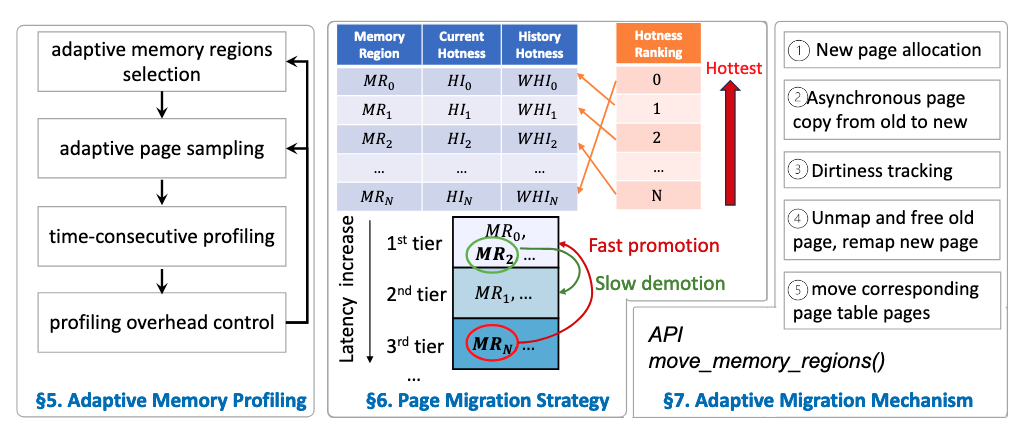
We contribute a page management system called MTM (Multi-Tiered Memory Management) that realizes these principles on large four-tier memory. MTM decouples the control of profiling overhead from the number of memory regions, connecting it directly with the number of PTE (Page Table Entry) scans. This allows profiling quality and overhead to be distributed proportionally according to the variation of both spatial and temporal locality (how close data accesses are in memory and time).
MTM breaks the barrier that blocks the construction of a universal page-migration policy across tiers. It uses overhead-controlled, high-quality profiling to establish a global view of all memory regions in all tiers and considers all NUMA distances to decide page migration. In particular, MTM enables a "fast promotion and slow demotion" policy for high performance. Hot (frequently-accessed) pages identified in all lower tiers are ranked and directly promoted to the top tier, minimizing data movement through tiers. When a page is migrated out of the top tier to accommodate hot pages, it's moved to the next lower tier with available space.
Running the Experiment on Chameleon
To test MTM, we use a Chameleon node with four NUMA nodes. These NUMA nodes provide a four-tier memory system for our study. We find that Chameleon's hardware catalog is very useful for finding such a machine. There aren't many machines available like this in the Chameleon cloud, so using the hardware catalog helps us quickly find what we need.
Experiment Artifacts
Our paper on this research, MTM: Rethinking Memory Profiling and Migration for Multi-Tiered Large Memory, has been published in EuroSys'24.
User Interview

Tell Us About Yourself!
I'm Dong Li, an associate professor at University of California, Merced. My research focuses on high-performance computing (HPC), particularly memory systems in HPC and building efficient HPC systems to support AI/ML workloads.
My dream is to make HPC systems more scalable and more approachable by regular people.
Do you have any advice for budding researchers?
To students beginning their research journey, my advice is: Be patient and go deep into the research.
How do you deal with research challenges?
When facing challenges like paper rejections, I've learned to be patient and persistent, while being open-minded to reviewers' comments. These experiences have influenced my future work direction by helping me choose research topics more carefully.
Why did you choose this field of research?
I chose this direction of research because it aligns with my vision of future systems becoming more disaggregated and intelligent.
Looking ahead, we're seeking testbeds with more NUMA nodes and larger memory capacity. Given the upcoming CXL (Compute Express Link) memory, a new technology for high-speed CPU-to-device and CPU-to-memory connections, we're also looking for testbeds with CXL memory components to improve our experiments.
Thank you for sharing your research with the Chameleon community!
Exploring Process-in-memory Architecture for High-performance Graph Pattern Mining
- June 20, 2022 by
- Rujia Wang
Graph Pattern Mining (GPMI) applications are considered a new class of data-intensive applications -- they generate massive irregular computation workloads and pose memory access challenges, which degrade the performance and scalability significantly. Researchers at the Illinois Institute of Technology approach the problem by using the emerging process-in-memory architecture.
No comments